
Experimenting with hyper-parameter tuning in a neural-network using Jupyter and Voila
A couple of days ago, I saw a post on LinkedIn which mentioned a library called Voila that serves Jupyter (IPython) widgets in an HTML format.
I’ve been using Jupyter notebooks as part of learning data-science skills (in particular, deep-learning frameworks) for about a year now, but this was the first time I heard of widgets in the same context. This picqued my interest, because for me, Jupyter notebooks had always been Markdown + Python + Graphs/plots. Sure, you can “interact” with a Jupyter notebook by modifying your code and re-running the cells (even execute them out-of-order), but you lose that feature when you end up exporting it to static HTML. What you see in an HTML output is nothing other than the text version of your Jupyter notebook. What this means is that you can only read the code, but neither can you run nor can you modify it.
So it appeared to me that finally, I could actually add a more sensible form of interaction to a Jupyter notebook-based web page using IPython widgets. And the first application I could think of was about hyper-parameter tuning of a tou neural-network for didactic purposes.
Background:
In machine-learning, neural-networks are all the rage these days. Thanks to deep and intelligent architectures (read: more layers), state-of-the-art neural-networks can achieve super-human performance on Image classification, beat humans at the most complex board-game and even sound like actual humans, good enough to pass the Turing test!
But that performance doesn’t come without its own costs. Neural networks have various attributes that decide their performance on metrics such as accuracy, recall, training-time, memory consumption, inference speed, etc. A good neural-network should be able to solve a problem in a time less than what it takes for a human on the same specific task. Admittedly, neural-nets are much faster and usually quite accurate with their inferences. But for such runtime guarantees, such networks are trained for prolonged periods, and even then, continuous experimentation and several iterations are required before the final result is good enough for the job.
But, like all experiments, neural-network training also has a few rules-of-thumb, which when followed, can help in reaching good results faster rather than starting every experiment from scratch.
Of the several ways for improving the accuracy and performance of a neural-network, hyperparameter tuning (or optimization) is something that is done once a preliminary network-architecture starts showing good results, but needs to be “tuned” before it can perform close to its maximum potential on the problem. But hyperparamter tuning comes with experience, generally requires a few iterations and differs from one problem to the next.
Idea
In the context of neural-networks, there are several hyperparameters that are adjusted, such as:
- batch-size
- number of layers
- neurons in a layer
- regularization function and parameters (e.g. dropout percentage)
- optimizer parameters
- step-size
- learning-rate
- decay-rate
- activation function
- convolution and pooling kernel size (CNN only)
As a simple example, I chose a 5-layer fully-connected neural-network, that trains on the MNIST dataset, and produces a final output of class probabilities of the input pixels belonging to a particular type of digit (between 0 and 9, inclusive).
Here’s the neural network visualized:
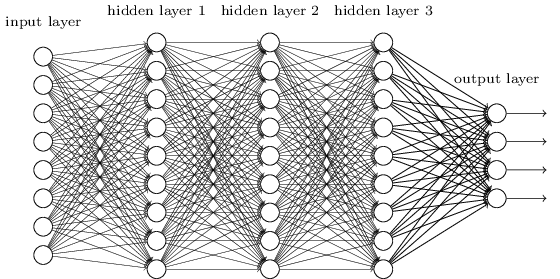
For the purpose of project, I selected these paramters to be tunable:
- Batch size
- Size of first hidden layer
- Size of second hidden layer
- Size of third hidden layer
- Dropout probability
- Learning rate
- Number of epochs for training
Here’s how the tuning dashboard looks:

You can see the complete page, with the tuning dashboard, the resultant model and optimization function, along with buttons to train and test the whole setup here:
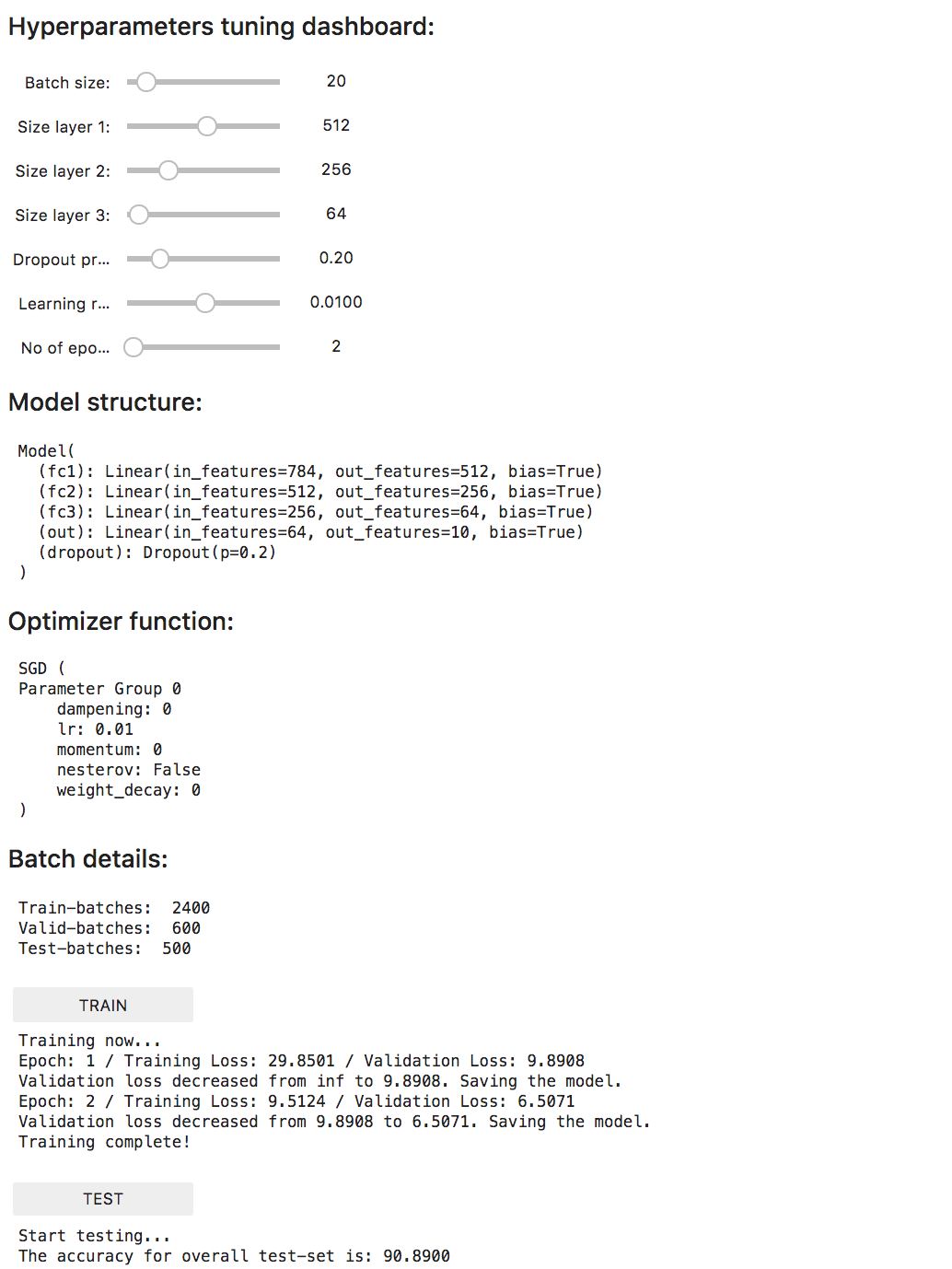
Now what
Well, you could adjust the sliders to different values and then try training and testing the network, to see how it affects the training time, validation error and the testing accuracy.
A few things I’ve observed:
- Smaller batch-size are more accurate (~20).
- Training more than, say, 50 epochs, gets very little increase in accuracy. And more or less, increases validation error. This is speciic to this use-case as this is a relatively shallow network (remember! hyperparamters depend on the network’s shape and architecture).
- Following a funnel-like model (sizeof(layer1) > sizeof(layer2) > sizeof(layer3)) gets good accuracy without being too slow on the training time.
But this is just scratching the surface. In actual real-world use-cases, hyperparameters are often tuned using a search-algorithm applied to a network which helps yield the best results without manual intervention.
But for someone who’s beginning to learn, this visual tool can serve as a nice and simple introduction to the practical aspects of training and running a neural-network. And the current version is just a minimal working example. There are several ways in which we can experiment here, even going so far as to have a GUI to edit the neural-network architecture itself! But that’s for another post.
Thanks for reading. Any suggestions regarding the project or bugs are welcome on its issue-tracker page on Github.
Peace ✌️